Autonomous inspection is a central problem in
robotics, with applications ranging from industrial monitoring
to search-and-rescue. Traditionally, inspection has often been
reduced to navigation tasks, where the objective is to reach
a predefined location while avoiding obstacles. However, this
formulation captures only part of the real inspection problem.
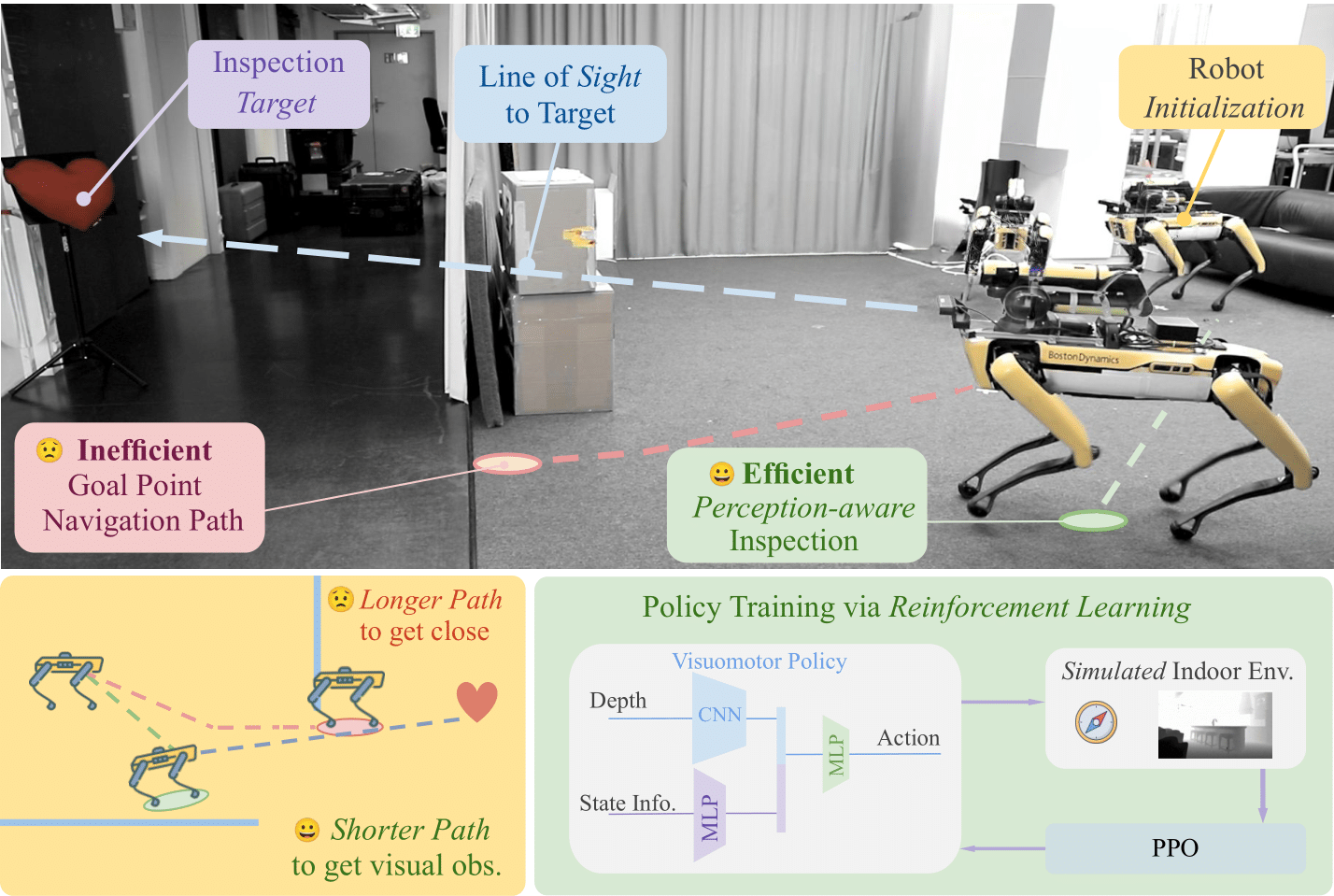
In real-world environments, the inspection targets may become
visible well before their exact coordinates are reached, making
further movement both redundant and inefficient.
What matters more for inspection is not simply arriving at the target’s
position, but positioning the robot at a viewpoint from which the
target becomes observable. In this work, we revisit inspection
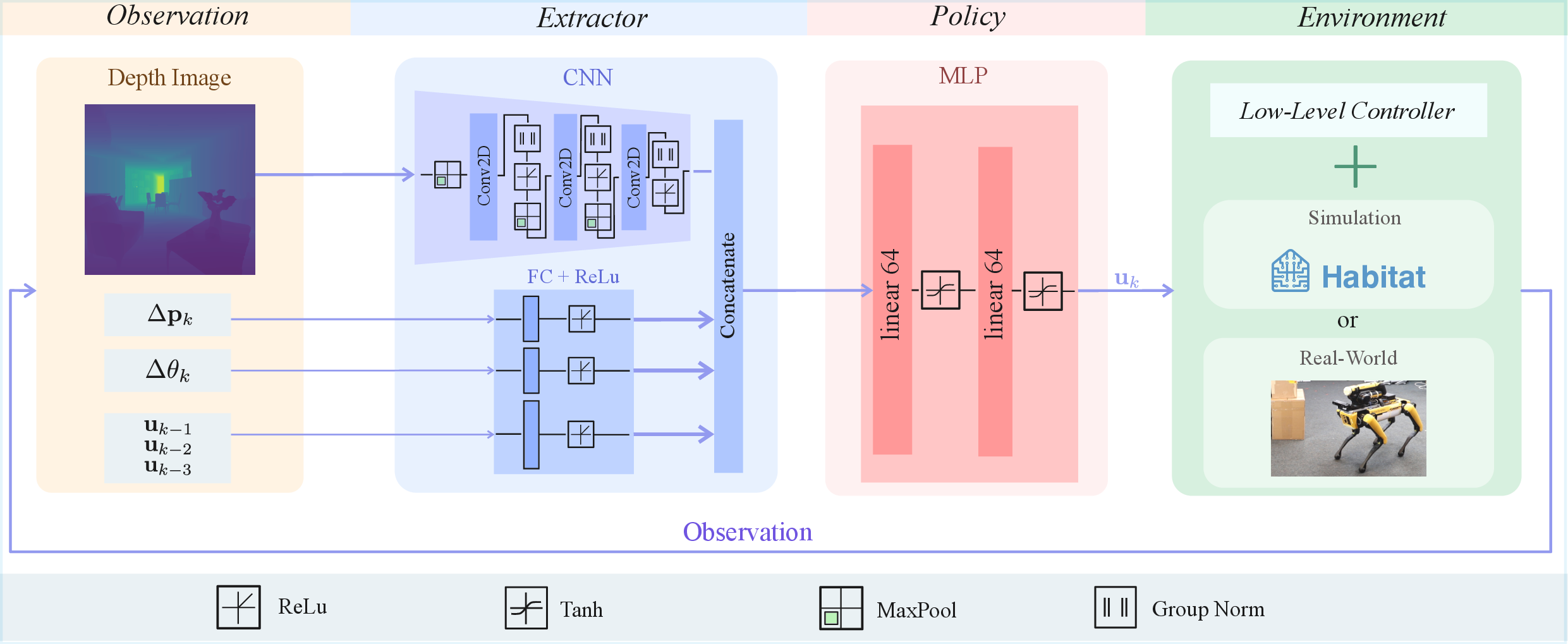
from a perception-aware perspective. We propose an end-to-end
reinforcement learning framework that explicitly incorporates
target visibility as the primary objective, enabling the robot
to find the shortest trajectory that guarantees visual contact
with the target without relying on a map. The learned policy
leverages both perceptual and proprioceptive sensing and is
trained entirely in simulation, before being deployed to a real-
world robot. We further develop an algorithm to compute
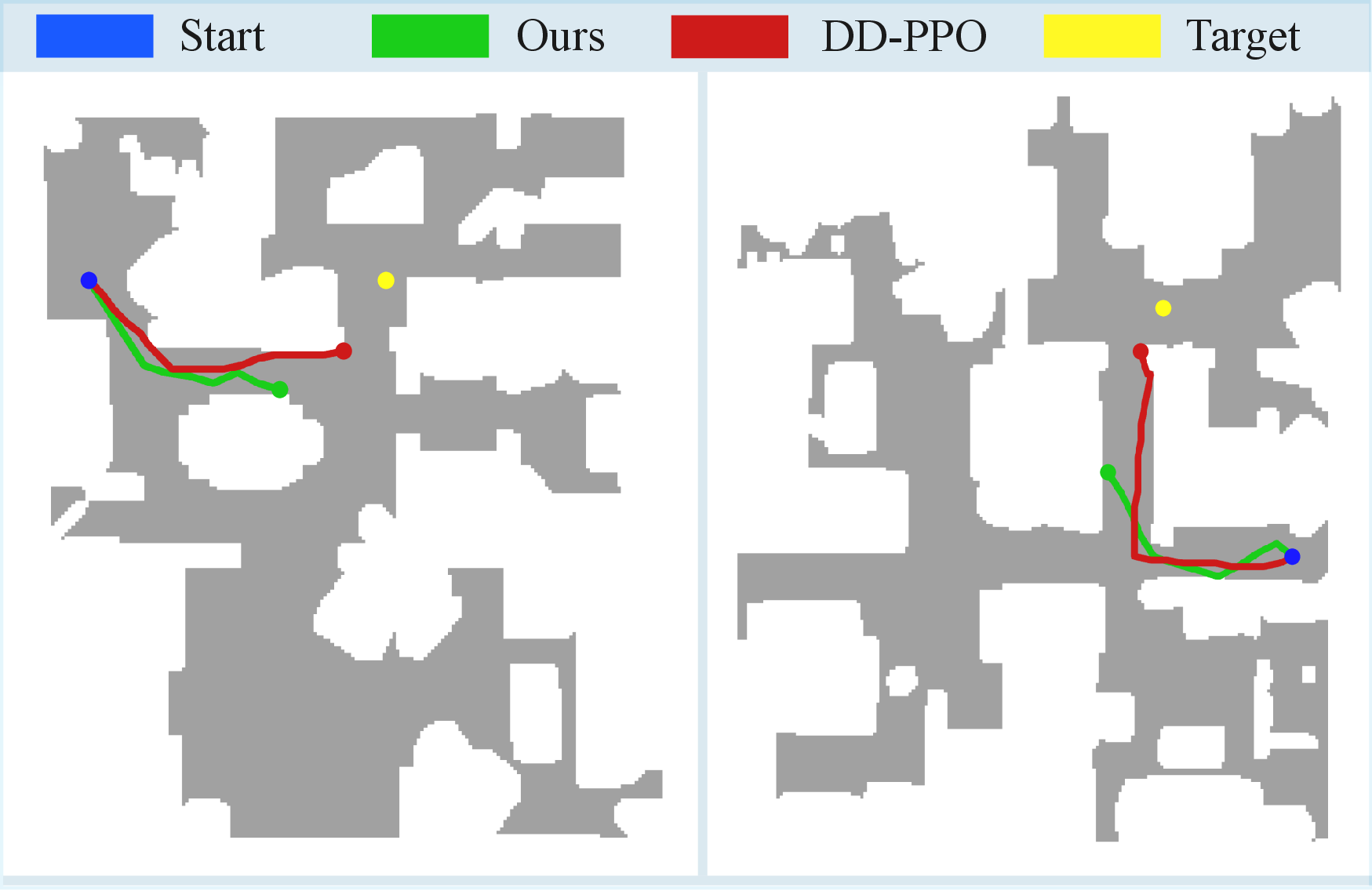
ground-truth shortest inspection paths, which provides a ref-
erence for evaluation. Through extensive experiments, we show
that our method outperforms existing classical and learning-based
navigation approaches, yielding more efficient inspection
trajectories in both simulated and real-world settings.